
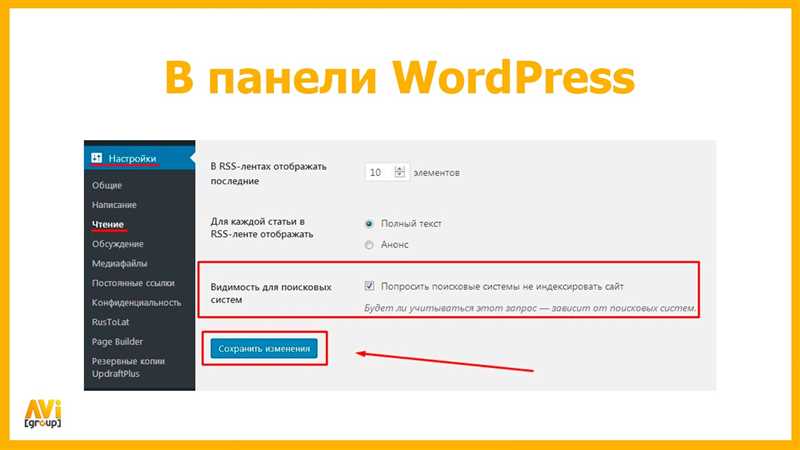
В современном интернете с ростом числа сайтов и их разнообразия, многим владельцам веб-ресурсов приходится сталкиваться с необходимостью скрыть свой сайт от поисковых систем. Узнать, как закрыть сайт от индексации, может быть полезно, если вы хотите временно ограничить доступ к сайту для обновления и исправления ошибок, или по другим причинам.
К счастью, защитить свой сайт от индексации от поисковых систем довольно просто. Существуют несколько способов, которые вы можете использовать в зависимости от ваших потребностей и уровня технической осведомленности. В этой статье мы рассмотрим наиболее распространенные и эффективные методы по закрытию сайта от индексации. Это поможет вам сохранить конфиденциальность информации или временно скрыть сайт от широкой публики.
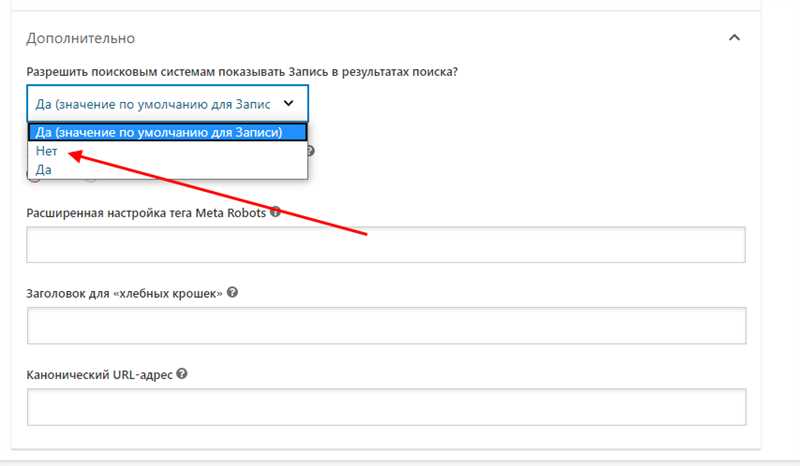
Один из наиболее простых способов закрыть сайт от индексации — это использование файла robots.txt. Данный файл находится в корневой директории вашего сайта и содержит инструкции для поисковых роботов. Если вы хотите, чтобы поисковые системы не индексировали ваш сайт, вы можете добавить «disallow: /» в файл robots.txt. Это позволит поисковым роботам знать, что ваш сайт закрыт для индексации.
Использование файла robots.txt
В файле robots.txt используется специальный синтаксис, состоящий из нескольких элементов. Каждое правило начинается с указания «User-agent:», где последует имя поискового робота, к которому относится данное правило. Далее можно использовать такие команды, как «Disallow:», «Allow:», «Sitemap:», «Crawl-delay:» и другие, для задания требуемых ограничений.
Пример использования файла robots.txt
Ниже приведен пример простого файла robots.txt:
User-agent: * Disallow: /private/ Disallow: /admin/ Disallow: /tmp/ Allow: /public/
В данном примере указывается, что для всех поисковых роботов (User-agent: *) необходимо запретить индексацию страниц, находящихся в разделах /private/, /admin/ и /tmp/. Однако, раздел /public/ оставляется доступным для индексации (Allow: /public/).
Файл robots.txt должен быть расположен в корневой директории вашего сайта и доступен по прямой ссылке (например, http://www.example.com/robots.txt). При наличии нескольких поддоменов или отдельных страниц, требующих различных правил, можно создать отдельные файлы robots.txt и разместить их в соответствующих поддиректориях.
Мета-тег noindex
| <meta name=»robots» content=»noindex»> |
Таким образом, при обращении поисковой системы к странице сайта с данным мета-тегом, она игнорирует контент данной страницы и не добавляет его в свою базу данных. Это позволяет предотвратить индексацию страницы и скрыть ее от общедоступного поиска.
Использование директивы noindex для страниц
Для использования директивы noindex необходимо внедрить в код страницы мета-тег со следующей записью: <meta name=»robots» content=»noindex»>. Этот тег должен идти в секции <head> страницы, между открывающим и закрывающим тегами.
Применение директивы noindex полезно в нескольких случаях:
- Страницы, содержащие конфиденциальную информацию, которую не следует отображать в результатах поиска;
- Страницы с временным или устаревшим контентом;
- Группы страниц, созданные для тестирования или разработки;
- Страницы, содержащие информацию о товарах или услугах, которые больше не предлагаются.
Использование директивы noindex может помочь улучшить ранжирование сайта в поисковых системах, исключив из индекса страницы, которые не имеют значимости для пользователей.
| Преимущества | Недостатки |
|---|---|
|
|
В итоге, использование директивы noindex является эффективным инструментом для контроля индексации ваших страниц сайта. Оно помогает улучшить пользовательский опыт, обеспечить конфиденциальность и сосредоточить внимание поисковых систем на наиболее значимых страницах.
Наши партнеры: